Uso de IA para conectar incidentes de IA
La base de datos de incidentes de IA (AIID) lanzada públicamente en noviembre de 2020 como un panel de control de los daños de IA realizados en el mundo real. Inspirada en bases de datos similares en la industria de la aviación, su tesis del cambio se deriva del aforismo de Santayana: “Aquellos que no pueden recordar el pasado están condenados a repetirlo”. Después de acumular una colección de 1600 informes de incidentes, el AIID tiene mucha "historia" registrada y un nuevo conjunto de problemas: comprender las tendencias y las relaciones entre incidentes y garantizar que no aceptemos varias copias del mismo incidente. Por lo tanto, nos propusimos desarrollar una herramienta para facilitar la conexión y categorización de la historia emergente de los daños de la IA.
Esta es una publicación de invitado escrita por tres miembros de un equipo Capstone de la Universidad Estatal de Oregón (OSU), que incluye Nicholas Broce, Nicholas Olson y Jason Scott-Hakanson.[^1]
La herramienta más nueva en la caja
Cada incidente en AIID es una colección de informes de noticias sobre el mismo evento, y cada una de estas colecciones recibe una "ID de incidente" única. Creamos una herramienta que aplica una red neuronal a todos los informes de incidentes nuevos y devuelve el incidente más relacionado semánticamente, de acuerdo con la red neuronal. Por ejemplo, ingresemos un informe de un accidente automovilístico de Tesla y veamos qué devuelve la red neuronal como más relacionado,
Este ejemplo se basa en la API que toma texto de entrada arbitrario y genera los ID de los incidentes más similares en la base de datos. La API está siendo utilizada actualmente por los editores de AIID cuando ya hay nuevos envíos en la base de datos. También está planificado para futuros casos de uso, que incluyen:
- sembrando todos los incidentes con un panel de "Incidente similar"
- visualizando gráficamente relaciones entre incidentes en el AIID
- identificar automáticamente los informes de noticias que se agregarán a la base de datos
En las pruebas, el modelo de Longformer tuvo una precisión de alrededor del 94 % al correlacionar los informes de exclusión en la base de datos con sus propios ID de incidentes. El modelo es especialmente preciso con informes de noticias o textos de entrada igualmente largos, y menos con textos de entrada más cortos. Esperamos abordar estos y otros problemas en futuras iteraciones.
El proyecto es de código totalmente abierto y está construido para ser modular, extensible y fácil de cambiar para el desarrollo futuro. Los nuevos modelos, las nuevas técnicas y las nuevas funciones se pueden agregar y se agregarán fácilmente a esta API para satisfacer las necesidades futuras.
Si desea obtener más información sobre cómo se construyó este proyecto, cómo funciona, sus limitaciones actuales y cómo puede contribuir, consulte nuestro apéndice sobre los detalles técnicos.
¡Inténtalo tú mismo!
Puede encontrar la primera integración de esta herramienta disponible en el formulario de envío de informes, y lo alentamos a que juegue con ella y explore los artículos que encuentre. En el sitio web, desplácese hacia abajo hasta el campo etiquetado como "texto" e ingrese un texto de al menos 256 caracteres sin espacios. Después de un breve tiempo de cálculo, los artículos aparecerán en el cuadro denominado "Incidentes relacionados semánticamente" en la parte inferior de la página.
Créditos
- Iz Beltagy, Matthew E. Peters, Arman Cohan en AllenAI para el modelo Longformer como alojado en Huggingface
- Luna McNulty y Sean McGregor por el trabajo de front-end continuo que interactúa con la API
[^1]: Habiendo completado su culminación, todos los autores comenzarán a trabajar en ingeniería de software este verano, con Nicholas Broce en Garmin AT, Nicholas Olson en Cognex y Jason Scott-Hakanson en ** Investigación Lam**.
Apéndice
Haga clic para mostrar/ocultar los detalles técnicos
Solución AWS
Para admitir una correlación de similitud escalable, asíncrona y rápida, esta implementación utiliza una pila completa de herramientas de AWS, todas creadas e implementadas con AWS CDK v2. El lado de AWS de la solución consiste principalmente en una colección de AWS Lambdas y una API RESTful HTTP de AWS API Gateway. Este sistema y la cadena de compilación se diseñaron para ser altamente modulares y ampliables, de modo que se pudieran agregar nuevas funciones de Lambda o funciones de API en cualquier momento. Además, el modelo Longformer se puede cambiar fácilmente por otro modelo previamente entrenado o ajustado, de modo que el desarrollo futuro pueda ir en la dirección que mejor apoye el crecimiento de la base de datos.
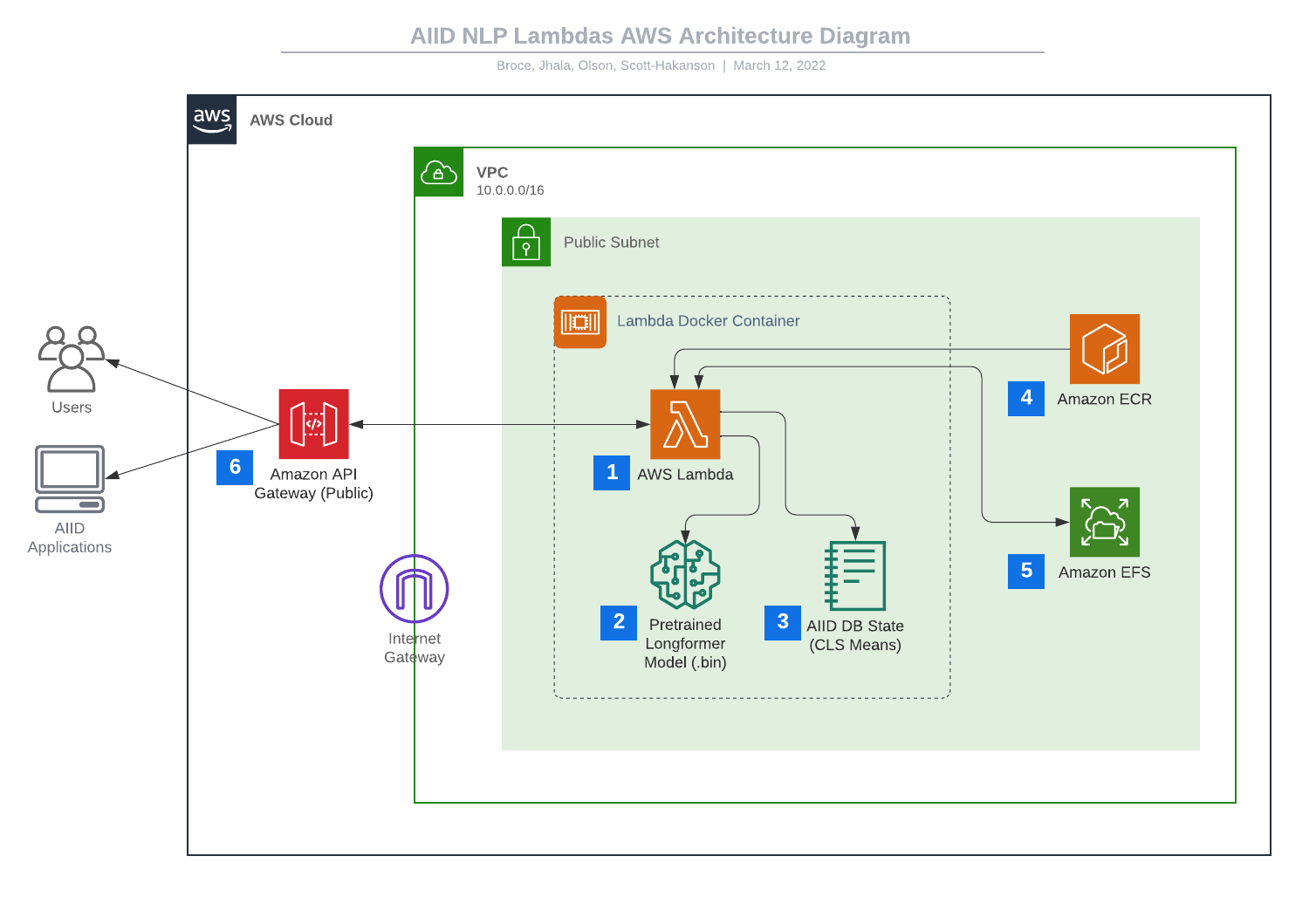
- AWS Lambda → 2. Modelo LongFormer preentrenado (.bin), 1. AWS Lambda → 3. Estado de base de datos AIID (CLS Means), 4. Amazon ECR → 1. AWS Lambda, 1. AWS Lambda ↔ 5. Amazon EFS, 6. Amazon API Gateway (público) ↔ 1. AWS Lambda, 6. Amazon API Gateway (público) → Usuarios, 6. Amazon API Gateway (público) → Aplicaciones AIID. Los elementos 1 a 3 están dentro de un cuadro con la etiqueta "Contenedor Lambda Docker". Los elementos del 1 al 5 están dentro de un cuadro con la etiqueta VPC 10.0.0/16. En el borde de ese cuadro hay un ícono que muestra un marco de puerta con la etiqueta "Internet Gateway". Dentro de ese cuadro hay otro marcado con un icono de candado con la etiqueta "Subred pública". Los elementos del 1 al 6 están dentro de un cuadro etiquetado como "nube de AWS".
Estas funciones modulares de Lambda realizan porciones o fragmentos completos de los diferentes cálculos que componen el proceso de texto a incidente similar. Actualmente, el sistema aloja algunas funciones de Lambda, cada una con un punto final dedicado en la API:
-
/text-to-db-similar: que utiliza una instancia de Longformer para procesar el texto del informe de entrada y generar una lista de los ID de incidentes más similares -
/embed-to-db-similar: que toma una incrustación de Longformer preprocesada para un texto de informe y escupe una lista de los ID de incidentes más similares

Estas Lambdas son potentes porque se puede activar y ejecutar una cantidad arbitraria de instancias en cualquier momento con una latencia increíblemente baja, ya que se construyen como imágenes Docker independientes con todos preempaquetado y sin necesidad de acceso a Internet externo.
Solución de PNL
Esta solución utiliza el modelo Long Document Transformer preentrenado de AllenAI (Longformer) para procesar entradas de consultas y también para mantener una representación basada en el estado de cada incidente en el AIID. Longformer está diseñado específicamente para admitir secuencias de entrada largas, lo que lo hizo ideal para nuestros propósitos.

Cuando se realiza una consulta a /text-to-db-similar, la API Lambda usa una instancia local de Longformer para tokenizar el texto de entrada y procesarlo en un conjunto de vectores de alta dimensión. La longitud de este conjunto es igual al número de tokens en la entrada. El primer token de cada incrustación es un token de clasificación especial (CLS) y, cuando se procesa, conserva cierta información latente sobre la naturaleza de la incrustación. Esta representación latente se compara utilizando la similitud del coseno con las incrustaciones que se procesan previamente para cada incidente actualmente en la base de datos, y los incidentes con la mayor similitud se devuelven como posibles candidatos.
Las incorporaciones con las que se compara la entrada de la consulta se generan de forma asincrónica al obtener informes recién agregados del AIID, procesarlos con Longformer y realizar un promedio ponderado entre el estado anterior del incidente relacionado con el informe y la nueva incorporación. De esta forma, la representación latente para un incidente es el promedio de las representaciones de cada uno de sus informes relacionados. Idealmente, este enfoque conduce a una mayor precisión con el tiempo a medida que se agregan más datos y sigue siendo escalable, ya que el estado se puede actualizar en cualquier momento utilizando pocos recursos.
Limitaciones actuales
El estado de lanzamiento de este nuevo sistema tiene algunas limitaciones notables que es importante tener en cuenta:
-
El sistema actualmente solo contiene un puñado de Lambdas, pero fue construido para ser altamente modular, por lo que las nuevas incorporaciones están en el horizonte inminente para este proyecto.
-
Hemos notado un sesgo potencial en el sistema donde las identificaciones de incidentes que tienen menos informes existentes pueden tener menos probabilidades de lograr puntajes de similitud altos. Esto requiere más investigación y probablemente solo se aplicaría en nuestra demostración actual de similitud de algún texto de entrada para cada uno de los ID de incidentes, a diferencia de los informes de incidentes individuales.
-
Longformer tiene un límite en la longitud del texto de entrada que puede procesar, y cuanto más se amplía este límite, más lenta se vuelve la inicialización/correlación y más recursos demanda el modelo. Por estas razones, el sistema actualmente solo procesa los primeros 2000 tokens (aproximadamente 2000 palabras) de cada texto de entrada proporcionado. Esto es más que suficiente para casi todos los textos de la base de datos, pero se puede modificar fácilmente para Lambdas individuales en el futuro.
-
El procesamiento de Longformer del texto del informe funciona al comparar la comprensión holística del texto del modelo, lo que lleva a que surjan algunas peculiaridades en el uso. Específicamente, cabe destacar que el modelo tiende a conceptualizar segmentos cortos mentos de texto y artículos más largos de manera diferente, lo que lleva al ejemplo actual de integración del sistema que da resultados poco intuitivos para entradas muy cortas de unas pocas oraciones. Actualmente, este sistema no (intenta) reemplazar el sistema de búsqueda de Algolia que utiliza la aplicación Discover
¿Quiero ayudar?
Si desea ayudar a que esta herramienta crezca y mejore o desea modificar los sistemas que hemos configurado, puede encontrar todo el código en el repositorio de GitHub.