Utiliser l'IA pour connecter les incidents d'IA
La AI Incident Database (AIID) lancée publiquement en novembre 2020 en tant que tableau de bord des dommages causés par l'IA dans le monde réel. Inspirée de bases de données similaires dans l'industrie aéronautique, sa thèse du changement est dérivée de l'aphorisme de Santayana, "Ceux qui ne peuvent pas se souvenir du passé sont condamnés à le répéter". Après avoir amassé une collection de 1 600 rapports d'incidents, l'AIID a beaucoup "d'historique" et un nouvel ensemble de problèmes : comprendre les tendances et les relations entre les incidents et s'assurer que nous n'acceptons pas plusieurs copies du même incident. Nous avons donc entrepris de développer un outil pour faciliter la connexion et la catégorisation de l'histoire émergente des méfaits de l'IA.
Ceci est un article invité écrit par trois membres d'une équipe de l'Oregon State University (OSU) Capstone, y compris Nicholas Broce, Nicholas Olson et Jason Scott-Hakanson.[^1]
Le nouvel outil dans la boîte
Chaque incident dans l'AIID est une collection de reportages sur le même événement, et chacune de ces collections reçoit un "identifiant d'incident" unique. Nous avons construit un outil qui applique un neural network à tous les nouveaux rapports d'incidents et renvoie l'incident le plus sémantiquement lié, en fonction du neural network. Par exemple, saisissons un rapport d'accident de voiture Tesla et voyons ce que le réseau de neurones renvoie comme le plus lié,
Cet exemple est construit autour de l'API qui prend un texte d'entrée arbitraire et génère les ID des incidents les plus similaires dans la base de données. L'API est actuellement utilisée par les éditeurs AIID lorsque de nouvelles soumissions sont déjà dans la base de données. Il est également prévu pour de futurs cas d'utilisation, notamment :
- semer tous les incidents avec un panneau "Incident similaire"
- visualiser graphiquement les relations entre les incidents dans l'AIID
- identification automatique des reportages à ajouter à la base de données
Lors des tests, le modèle Longformer était précis à environ 94 % pour corréler les rapports "laisser un de côté" dans la base de données avec leurs propres ID d'incident. Le modèle est particulièrement précis avec des reportages ou des textes d'entrée de même longueur, et moins avec des textes d'entrée plus courts. Nous espérons résoudre ces problèmes et d'autres dans les prochaines itérations.
Le projet est entièrement open source et est conçu pour être modulaire, extensible et facilement modifiable pour un développement futur. De nouveaux modèles, de nouvelles techniques et de nouvelles fonctionnalités peuvent et seront facilement ajoutés à cette API pour répondre aux besoins futurs.
Si vous voulez en savoir plus sur la construction de ce projet, son fonctionnement, ses limites actuelles et comment vous pouvez y contribuer, consultez notre annexe sur les détails techniques !
Essayez-le vous-même !
Vous pouvez trouver la première intégration de cet outil disponible sur le formulaire de soumission de rapport, et nous vous encourageons à jouer avec et à explorer les articles que vous trouvez. Sur le site Web, faites défiler jusqu'au champ intitulé "texte" et saisissez un texte d'au moins 256 caractères autres que des espaces. Après un court temps de calcul, les articles apparaîtront dans la case intitulée "Incidents sémantiquement liés" en bas de la page.
Crédits
- Iz Beltagy, Matthew E. Peters, Arman Cohan à AllenAI pour le modèle Longformer comme [hébergé sur Huggingface](https://huggingface.co/docs/transformers/model_doc/ ancien)
- Luna McNulty et Sean McGregor pour le travail frontal en cours sur l'interface avec l'API
[^1] : Après avoir terminé leur synthèse, les auteurs commenceront tous à travailler sur le génie logiciel cet été, avec Nicholas Broce chez Garmin AT, Nicholas Olson chez Cognex et Jason Scott-Hakanson chez ** Recherche Lam**.
Annexe
Cliquez pour afficher/masquer les détails techniques
Solution AWS
Pour prendre en charge une corrélation de similarité évolutive, asynchrone et rapide, cette implémentation utilise une pile complète d'outils AWS, tous créés et déployés à l'aide d'AWS CDK v2. Le côté AWS de la solution se compose principalement d'une collection d'AWS Lambdas et d'une API HTTP AWS API Gateway RESTful. Ce système et cette chaîne de construction ont été conçus pour être hautement modulaires et extensibles, afin que de nouvelles fonctions Lambda ou fonctionnalités API puissent être ajoutées à tout moment. De plus, le modèle Longformer peut être facilement remplacé par un autre modèle pré-formé ou affiné, de sorte que le développement futur puisse aller dans la direction qui soutient le mieux la croissance de la base de données.
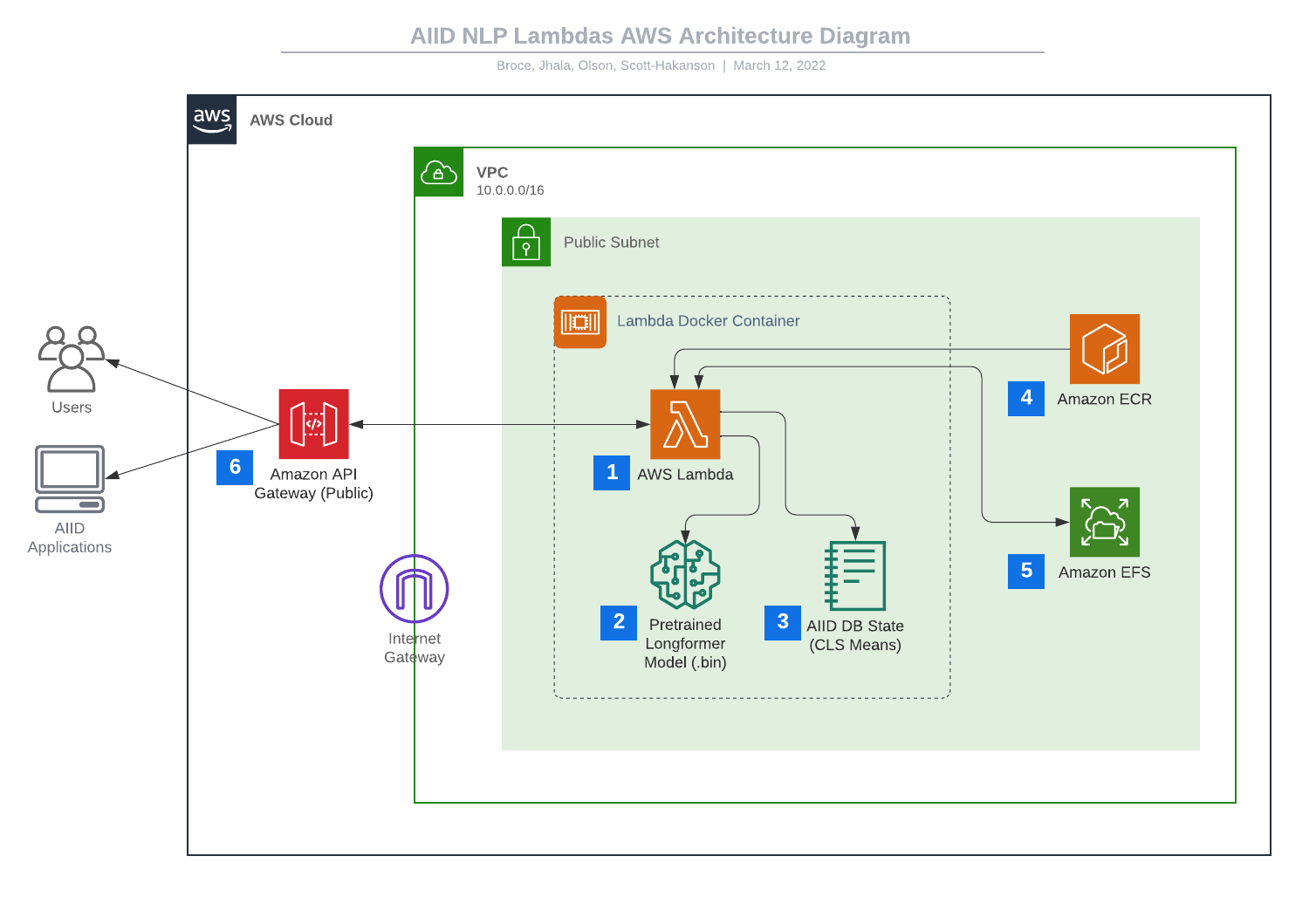
Ces fonctions Lambda modulaires remplissent des tranches ou des morceaux entiers des différents calculs qui composent le processus de conversion du texte en incident similaire. Actuellement, le système héberge quelques fonctions Lambda, chacune avec un point de terminaison dédié sur l'API :
-
/text-to-db-similar– qui utilise une instance Longformer pour traiter le texte du rapport d'entrée et génére une liste des ID d'incident les plus similaires -
/embed-to-db-similar– qui prend une intégration Longformer prétraitée pour un texte de rapport et génére une liste des ID d'incident les plus similaires

Ces Lambdas sont puissantes car un nombre arbitraire d'instances peuvent être lancées et exécutées à tout moment avec une latence incroyablement faible, car elles sont construites en tant qu'images Docker autonomes avec toutes exigences pré-emballées et aucun accès requis à Internet.
Solution PNL
Cette solution utilise le modèle préformé de transformateur de long document (Longformer) d'AllenAI pour traiter les entrées de requête, ainsi que pour maintenir une représentation basée sur l'état de chaque incident dans l'AIID. Longformer est spécialement conçu pour prendre en charge de longues séquences d'entrée, ce qui le rend idéal pour nos besoins.

Lorsqu'une requête est adressée à /text-to-db-similar, l'API Lambda utilise une instance Longformer locale pour tokeniser le texte d'entrée et le traiter dans un ensemble de vecteurs de grande dimension. La longueur de cet ensemble est égale au nombre de tokens dans l'entrée. Le premier token de chaque incorporation est un token de classification spéciale (CLS) et, lorsqu'il est traité, il conserve certaines informations latentes sur la nature de l'incorporation. Cette représentation latente est comparée à l'aide de la similarité cosinus avec des incorporations qui sont prétraitées pour chaque incident actuellement dans la base de données, et les incidents avec la similarité la plus élevée sont renvoyés comme candidats probables.
Les intégrations auxquelles l'entrée de la requête est comparée sont générées de manière asynchrone en récupérant les rapports nouvellement ajoutés à partir de l'AIID, en les traitant à l'aide de Longformer et en effectuant une moyenne pondérée entre l'ancien état de l'incident associé au rapport et la nouvelle intégration. Ainsi, la représentation latente d'un incident est la moyenne des représentations de chacun de ses rapports associés. Idéalement, cette approche se traduit par une plus grande précision au fil du temps à mesure que davantage de données sont ajoutées et reste évolutive, car l'état peut être mis à jour à tout moment en utilisant peu de ressources.
Limites actuelles
L'état de lancement de ce nouveau système présente quelques limitations notables qu'il est important de noter :
-
Le système ne contient actuellement qu'une poignée de Lambda, mais a été conçu pour être hautement modulaire, de sorte que de nouveaux ajouts sont à l'horizon imminent pour ce projet.
-
Nous avons remarqué un biais potentiel dans le système où les ID d'incident qui ont moins de rapports existants peuvent être moins susceptibles d'atteindre des scores de similarité élevés. Cela nécessite plus de recherche et ne s'appliquerait probablement qu'à notre démonstration actuelle de la similitude de certains textes d'entrée avec chacun des ID d'incident, par opposition aux rapports d'incidents individuels.
-
Longformer a une limite à la longueur du texte d'entrée qu'il peut traiter, et plus cette limite est étendue, plus l'initialisation/corrélation est lente et plus le modèle demande de ressources. Pour ces raisons, le système ne traite actuellement que les 2 000 premiers tokens (environ 2 000 mots) de chaque texte d'entrée fourni. C'est plus que suffisant pour presque tous les textes de la base de données, mais peut facilement être modifié pour des Lambdas individuels à l'avenir.
-
Le traitement Longformer du texte du rapport fonctionne sur la comparaison de la compréhension holistique du texte par le modèle, ce qui entraîne l'apparition de quelques bizarreries lors de l'utilisation. Il convient de noter en particulier que le modèle a tendance à conceptualiser différemment les courts segments de texte et les articles plus longs, ce qui conduit à l'exemple actuel d'intégration du système donnant des résultats non intuitifs pour des entrées très courtes de quelques phrases. Actuellement, ce système n'essaie pas de remplacer le système de recherche Algolia utilisé par l'application Discover
Voulez-vous aider?
Si vous souhaitez aider cet outil à grandir et à s'améliorer ou si vous souhaitez bricoler les systèmes que nous avons mis en place, vous pouvez trouver tout le code [dans le référentiel GitHub](https://github.com/responsible-ai-collaborative /nlp-lambdas).